
Do you SQL? Salesforce Marketing Cloud

If you asked me “how do you find segmentation in Salesforce Marketing Cloud?” a few years ago, at the beginning of my experience with the tool, I would have rolled my eyes.
Yes, I said it, I would have rolled my eyes.
Why? Well, I am not a developer, I am not a coder and let’s say the user interface for segmentation in SFMC is quite limited compared to other technologies I have worked with in the past.
Sure, we can filter data extensions, split them, clone them and potentially use data relationship to connect multiple tables and cross filter them.
However, that day will come. The day in which none of the above will suffice and you will have to face an empty SQL activity and get the blank page syndrome.
I was lucky enough to find myself in this situation on my first assignment.
The architect I was working with was great and had a lot of knowledge, but also wanted me to fail and learn from my mistakes. He sent me to figure out how to create a segment that required to join 3 tables.
I got some directions from some of the devs in the offices, heard them talking about joins, left, right, inner, outer and I could even picture what they were referring to.
I started googling.
Brace yourself. The image I am about to share has been my guiding angel from the moment I found it and still is.

Save it now!
If you are a visual learner too, this will make the creation of segments with SQL much easier. So let’s get started.
Some technical background:
- SQL support for the SQL Query Activity is based on MS SQL Server 2005 capabilities
- The only supported operation is the SELECT statement. INSERT, UPDATE or DELETE are NOT allowed in the SQL statement
- The key thing to note is that it is a set based SQL whereby the output of your select statement should produce a result set (not storing it in temporary objects)
- The queries are case-insensitive for values and column names
- All operations are undertaken on data stored in data extensions or system data views and results are always saved in data extensions
- The query executed as an isolated statement that cannot take input parameters from other activities or other processes
- DB server always operates in CST (Central Standard Time), this is the value populated as default for data extensions or if you use functions to retrieve current datetime
What do you need?

- Source: a data extension or a data view (data views store up to 6 months of the most important backend information for communications performance and subscribers, e.g. Sent, Subscribers etc)
- Destination: as mentioned above, the query result will be store in a data extension. Create this data extension ahead of writing the query.
Note this data extension should contain all the fields you are planning to use for your segmentation.
Tip: If possible use exactly the same field label of your Source, the system will automatically map the source and the destination field.
If this is not possible you will need to use the “AS” statement in your query to force the mapping.
SELECT
FName AS FirstName
3. Query Activities: it’s time to try some SQL — navigate to Journey builder > automation studio > activities > SQL Queries


4. Run the query: now, you can run the activities from the SQL Query tab, however, you will not be able to troubleshoot. My advice is to create an automation flow, in automation studio, add your schedule (should be a time in the future) and the SQL query you have created, then click “Run Once”. In the Activity tab, you will be able to see if it was successful (green icon) or if it failed (red icon). Errors can be a bit vague, but they still provide some insight.
Let’s get to the code
Statements
1. SELECT: Used to select data from the database; In our case from data extensions or data views.
SELECT column1, column2, ...
FROM table_name
Replace column1, column2 with the field names you want to select from the source data extension.Replace table_name with the name of the source data extension.

In some examples online you will see the use of the * command, this selects all the available fields in the data extension.
SELECT *
This is a quick solution, however, it is not recommended. Salesforce advises selecting only the fields that are necessary by stating them separated by commas.
2. SELECT DISTINCT: Used to return only distinct (different) values. Inside a table, a column often contains many duplicate values; use select distinct if you only want to list the different (distinct) values.
SELECT DISTINCT column1, column2
FROM table_name
Replace column1, column2 with the name of the fields in table_name (source data extension) you would like to add to the resulting data extension (destination).
3. WHERE: Used to extract only those records that fulfil a specified condition. It is basically a filter.
SELECT column1, column2
FROM table_name
WHERE condition
Replace column1, column2 with the name of the fields in table_name (source data extension) you would like to add to the resulting data extension (destination).
3.1 WHERE Clause:

- Text VS Numeric values:
SQL requires single quotes around text values
SELECT column1, column2
FROM table_name
WHERE Country='Mexico'
However, numeric fields should not be enclosed in quotes:
SELECT column1, column2
FROM table_name
WHERE CustomerID=1
- AND, OR and NOT Operators: Used to filter records based on more than one condition:
The AND operator displays a record if all the conditions separated by AND are TRUE.
SELECT column1, column2
FROM table_name
WHERE condition1 AND condition2
AND condition3
For example, if you want to retrieve German records that live in Berlin, your query will look like the one in the below image. Using the AND operator will retrieve ONLY the German records that have Country = Germany and City = Berlin.

The OR operator displays a record if any of the conditions separated by OR is TRUE.
SELECT column1, column2
FROM table_name
WHERE condition1 OR condition2
OR condition3
For example, if you want to retrieve German records that live in Berlin but also German records that live in München, your query will look like the one in the below image. Using the OR operator will retrieve the German records that have Country = Germany and City = Berlin and also the German records that live in München.

The NOT operator displays a record if the condition(s) is NOT TRUE.
SELECT column1, column2
FROM table_name
WHERE NOT condition
For example, if you want to retrieve all records but the German, use “WHERE NOT” country=Germany. This will retrieve only non-German records as shown in the image below.

- NULL: A field with a NULL value is a field with no value. Retrieves records that don’t have a value in the column you are filtering with the WHERE statement.
SELECT column_names
FROM table_name
WHERE column_name IS NULL;

While NOT NULL is what you would use to exclude NULL values from the source data extension.
Only retrieves the records that have a value in the Column you are filtering with the WHERE statement
SELECT column_names
FROM table_name
WHERE column_name IS NOT NULL;
Now, my favorite part, The Joins
First, learn the structure: when building the SQL in SFMC you will
– always open with a SELECT statement
– then list the column names you want to retrieve (field names) separated by commans (,)
– define the FROM — this tells the system from which table (data extension or data view name) we are getting the data, add the name of the data extension or data view
Then we have few options:
– Option 1: we are working with 1 source only and we need to filter, in this case add the WHERE clause with the condition and you are done
– Option 2: we are working with more than 1 source and we need to join them and eventually cross filter. This is when you need to specify which type of join you need. In case of a join between one, or more tables, use the ON statement to link the tables, ON defines on which field the join is based (e.g. CustomerId, so both tables will contain a column with the CustomerId)
- Inner Join: selects records that have matching values in both tables.
For example, you want to select UK customers that have placed an order.
Table A represents your UK records (you have records from all over the world but you filter the records list to capture this subset), Table B contains all your orders. In order to get only the UK records that have placed an order, use the inner join. It will exclude the UK record that have NOT places an order and the order belonging to other countries.

SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name
When using joins it becomes important to specify to which table the column belongs to, you can specify the full name, followed by a dot (.) followed by the name of the column or assign to the table an index, like a letter, and use that before the (.) and the column name.
In the image below, the letter ‘a’ indicates the table “Orders” and columns that belong to this source. The letter ‘b’ is used to indicate the “Customers” and fields from the same table.

2. Left Join: Returns all records from the left table (table1), and the matched records from the right table (table2). The result is NULL from the right side if there is no match.
For example, you want to select all UK customers and see which one have placed an order.
Table A represents all your UK customers, Table B contains all your orders. In order to get all the UK records that have placed an order, use the right join. It will result in a data extension containing all the UK records and the order information for those that did place the order.

SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;
The right join does the opposite, retrieves all the data in table 2 and only those that are common between table2 and table1 from table1
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name = table2.column_name;
If applied at the left join scenario, where table1 is UK customer and table2 is order, the result would be all orders and only subscribers information for those UK records that have placed an order.

In order to retrieve only the records part of table1, that are not in common with table2, use a left join and apply a WHERE statement where, the unique Id of table 2, you are matching the records between the two tables, IS NULL. In this scenario, we are telling the system to create a join based on a unique key common to both table, but only return those from table1(a), that don’t have a match in table2(b).

3. Full Outer join: produces the set of all records in Table1 and Table2, with matching records from both sides where available.

SELECT column_name1,column_name2
FROM table1
FULL OUTER JOIN table2
ON table1.column_name = table2.column_name
4. To produce the set of records unique to Table A and Table B, we perform the same full outer join, then exclude the records we don’t want from both sides via a where clause.
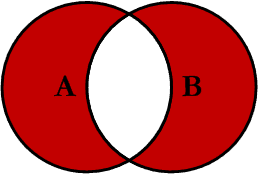
SELECT column_name(s)
FROM tableA
FULL OUTER JOIN tableB
ON tableA.Key = tableB.Key
WHERE tableA.KEY is NULL
OR tableB.column_name is NULL;
After reading this article you should be able to read and understand SFMC queries and be able to create your own.
If you don’t understand the foundation, you will not get it right, it is the same with every language.
You can find query examples online, but if you do not understand what these queries are doing you are basically trying to shoot an apple, blindfolded.
Below are some best practices and useful resources.
Note that Salesforce has also recently released an app called Query Studio, this allows users to run queries without having to create a data extension ahead of time, a life saver! A temporary data extension with 24hours data retention is created, change this setting if you want to retain the data for any longer. You can read more about query studio here.
If you do need any support with your queries, please feel free to reach out to me or Bluewolf, an IBM company.
Best Practice:
- For queries involving data views, implement with a 6-month cap.
- Often the performance is dramatically better limited to no more than 30 days.
- Think about the impact on the duration of that transaction, amount of transaction log growth, auto-kill, rollback, and extended database recovery times.
- A typical pattern works great in the beginning and as the amount of data grows so does the times to execute until AutoKill (30 minutes) gets involved.
- For target destinations (DEs), consider setting a retention period to minimize excessive growth.
- Stage the data! Break the work into pieces, if possible, or use an AltText Query Activity and implement with small, committed batches.
- Limit your update sets to one million records and batch through them.
- Avoid Data Extensions spanning a cumulative field width greater than 4000 characters.
Additional resources:
- Data views: https://help.salesforce.com/articleView?id=mc_as_data_views.htm&type=0
- Trailhead:https://trailhead.salesforce.com/en/content/learn/modules/marketing-cloud-data-management/query-data-with-sql
- App exchange: Query Studio
https://appexchange.salesforce.com/appxListingDetail?listingId=a0N3A00000FP3yFUAT - Benefits of Query Studio and how to use it by Zuzanna https://sfmarketing.cloud/2019/08/05/query-studio-for-marketing-cloud/
- Topics related to Data Views on Salesforce Stack Exchange
- Adam’s post about Troubleshooting Queries in SFMC

